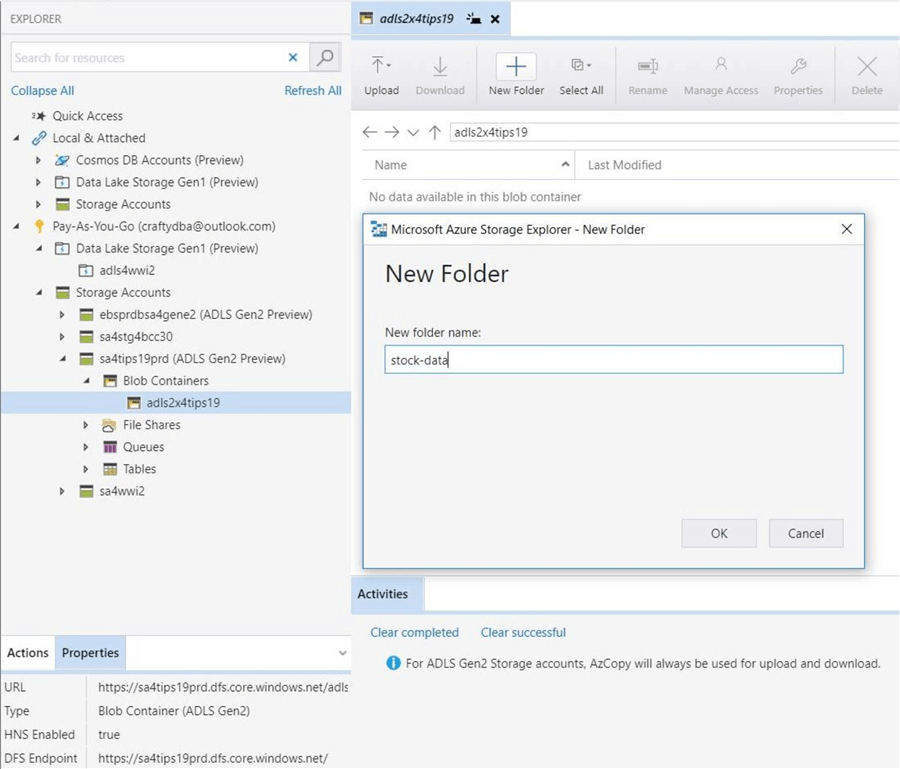
Adls gen2. Avoiding error 403 not when accessing ADLS Gen 2 from Azure Databricks while using a Service Principal 2019-12-01
Error while calling ADLS Gen 2 Rest API to create file

Please refer to the information in the www-authenticate header. This is most obvious when data is written to temporary directories which are renamed at the completion of the job. Tight integration with analytics frameworks results in an end to end secure pipeline. One of the great design pivots of big data analytics frameworks, such as Hadoop and Spark, is that they scale horizontally. The makes end-user authentication flow through the cluster and to the data in the data lake. I am able to generate Oauth token now successfully.
Next
Under the hood: Performance, scale, security for cloud analytics with ADLS Gen2

I tried out 3 cases : 1. But, what if you missed a step? With a correct authorization header. Please refer the below screenshots for reference : Right access token Wrong access token. Filter on App Registration 3. . Please let me know if anything else needs to be done to make this work.
Next
Connecting Power BI to ADLS Gen2
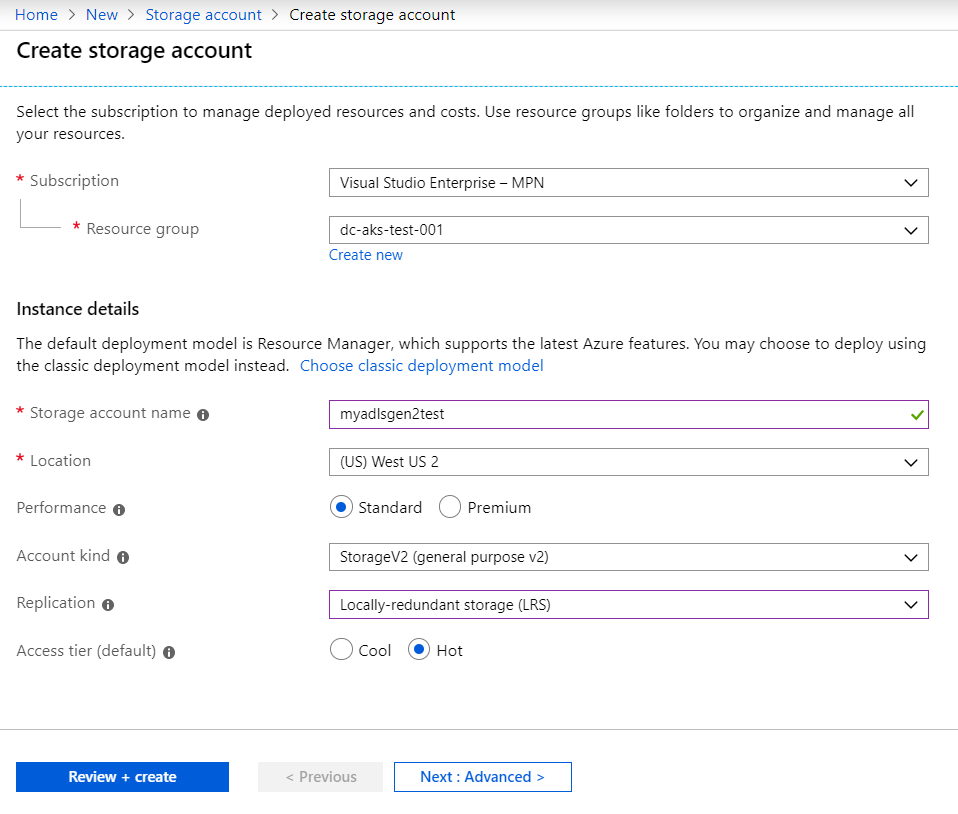
Enter a name in the Name box 5. Thankfully, this issue was fixed in and the fix is now included in the Databricks runtime 5. Hi James, yes your understanding is correct. Click on Azure Storage 7. Click on the name of your first app registration 7. While there is on the topic, I wanted to take an end-t0-end walkthrough the steps, and hopefully with this you can get everything working just perfectly! I also used the same to create filesystem and file. You can get that from the Azure Portal blade for Azure Active Directory.
Next
Azure Data Lake Storage Gen2 REST API reference
.jpg?width=1006&name=ModernDWReferenceArchitecture%20(002).jpg)
Filter on Azure Storage 6. Azure features services such as and for processing data, to ingress and orchestrate, , , and to consume your data in a pattern known as the Modern Data Warehouse, allowing you to maximize the benefit of your enterprise data lake. Please feel free to let me know if you need any additional details. The instructions to do this are well documented at the. Copy the Value of the generated client secret into a text editor Add required permissions Now you need to grant permission for your application to access Azure Storage. This, however, relies on the storage layer scaling linearly as well.
Next
Avoiding error 403 not when accessing ADLS Gen 2 from Azure Databricks while using a Service Principal
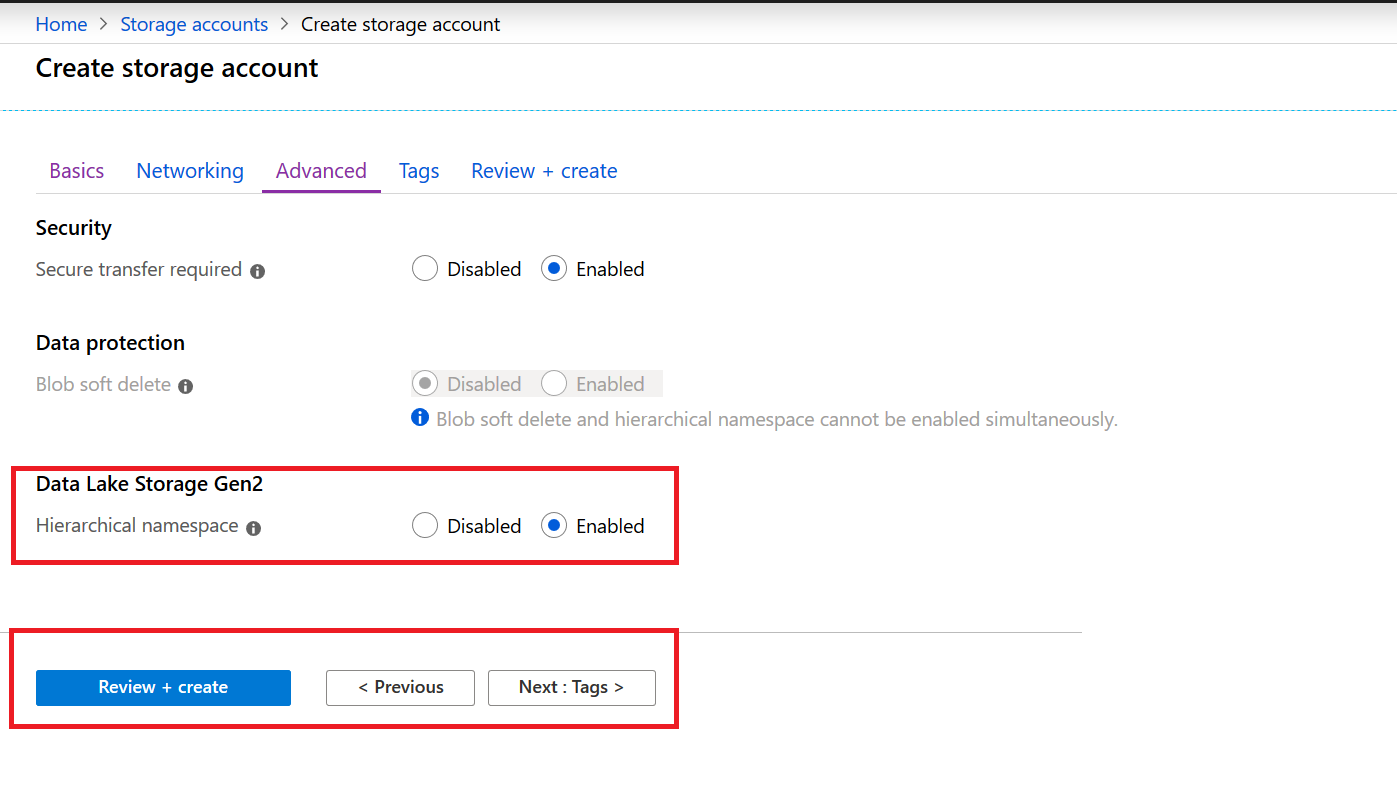
Register with Azure Active Directory tenant 1. Also notice the durability, which specifies the chances of losing data, which is incredibly small. Using the Service Principal from Azure Databricks Firstly, review the requirements from the official. Click on the application Settings 2. Azure Databricks is a first-party offering for Apache Spark. Looking forward to your response, thanks in advance.
Next
Azure Data Lake Storage Gen2 REST API reference
Enter Storage Blob Data Contributor in the Role box 4. Authorization header needs to have value : Bearer note the space between bearer and access token. The reason for this is simple, the more performant the storage layer, the less compute the expensive part! With an incorrect authorization header. For reference, here is what I did. Select In 1 year from the Expires box 5. Common mistakes could be : 1.
Next
Under the hood: Performance, scale, security for cloud analytics with ADLS Gen2
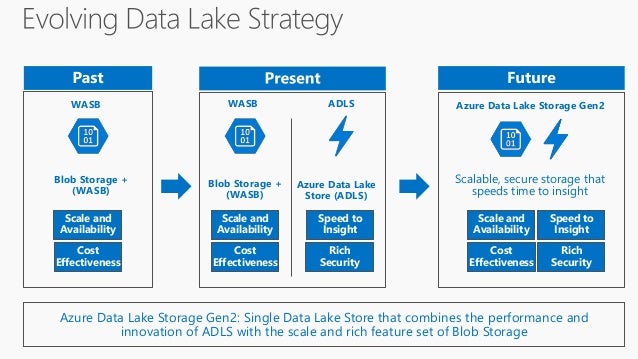
Azure is now the only cloud provider to offer a no-compromise cloud storage solution that is fast, secure, massively scalable, cost-effective, and fully capable of running the most demanding production workloads. To do this, I used to run the sample command below. Get started today and let us know your feedback. The rate of growth of big data analytics projects tend to be non-linear as a consequence of more diverse and accessible sources of data. Return to your storage account in the portal. Most likely you missed a folder or root-level permission assuming you gave the permission to the file correctly.
Next
How to backup Azure Data Lake Gen2 storage

However, this leads to design challenges such that the system must scale at the same rate as the growth of the data. Generate a client secret The next step is to create a client secret. Our mutual customers can take advantage of the simplicity of administration this storage option provides when combined with our analytics platform. Hi Roshan, The error is for sure related to the access token. It is designed to integrate with a broad range of analytics frameworks enabling a true enterprise data lake, maximize performance via true filesystem semantics, scales to meet the needs of the most demanding analytics workloads, is priced at cloud object storage rates, and is flexible to support a broad range of workloads so that you are not required to create silos for your data.
Next