Dbn. ジアザビシクロノネン 2020-01-23
Homepage Entrepose DBN

The process is as follows: 1. Iterate 2 and 3 for the desired number of layers, each time propagating upward either samples or mean values. Tips and Tricks One way to improve the running time of your code given that you have sufficient memory available , is to compute the representation of the entire dataset at layer i in a single pass, once the weights of the -th layers have been fixed. Hyper-parameters were selected by optimizing on the validation error. Keep this in mind when working with Theano. We use an unsupervised learning rate of 0. Fine-tuning took only 101 minutes or approximately 2.
Next
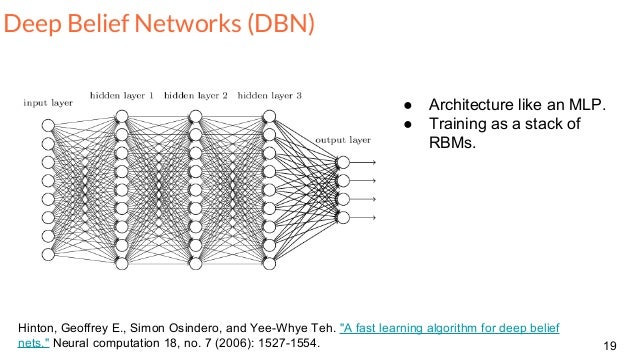
dbn
This is clear in all of their activities projects, operations, etc. On site, our safety policy is relayed daily with support from site supervision through a variety of initiatives. Use that first layer to obtain a representation of the input that will be used as data for the second layer. We will use the LogisticRegression class introduced in. Fine-tuning is then performed via supervised gradient descent of the negative log-likelihood cost function.
Next
Deep Belief Networks — DeepLearning 0.1 documentation

Since the supervised gradient is only non-null for the weights and hidden layer biases of each layer i. These loop over the entire validation set and the entire test set to produce a list of the losses obtained over these sets. We tested unsupervised learning rates in and supervised learning rates in. This representation can be chosen as being the mean activations or samples of. This corresponds to performing 500,000 unsupervised parameter updates. Examples of initiatives include Prestart Meetings, awareness campaigns tailored to specific risks, challenge contests, all of which are promoted through tools made available to employees, such as observation cards or mobile phone applications.
Next
Homepage Entrepose DBN

For the pre-training stage, we loop over all the layers of the network. . In this tutorial, we focus on fine-tuning via supervised gradient descent. With early-stopping, this configuration achieved a minimal validation error of 1. Note that the names of the parameters are the names given to the Theano variables e. We did not use any form of regularization besides early-stopping, nor did we optimize over the number of pretraining updates.
Next
DBN

. . . . . . .
Next
Deep Belief Networks — DeepLearning 0.1 documentation

. . . . . . .
Next
DBN
:format(jpeg):mode_rgb():quality(40)/discogs-images/L-20922-1549749067-7505.png.jpg)
. . . . .
Next
Deep Belief Networks — DeepLearning 0.1 documentation

. . . . . . .
Next
dbn

. . . . . .
Next