High accuracy due to the precise splitting unpaired two-sample. Unpaired (Two Sample) t Test 2020-01-13
Accuracy vs. Precision
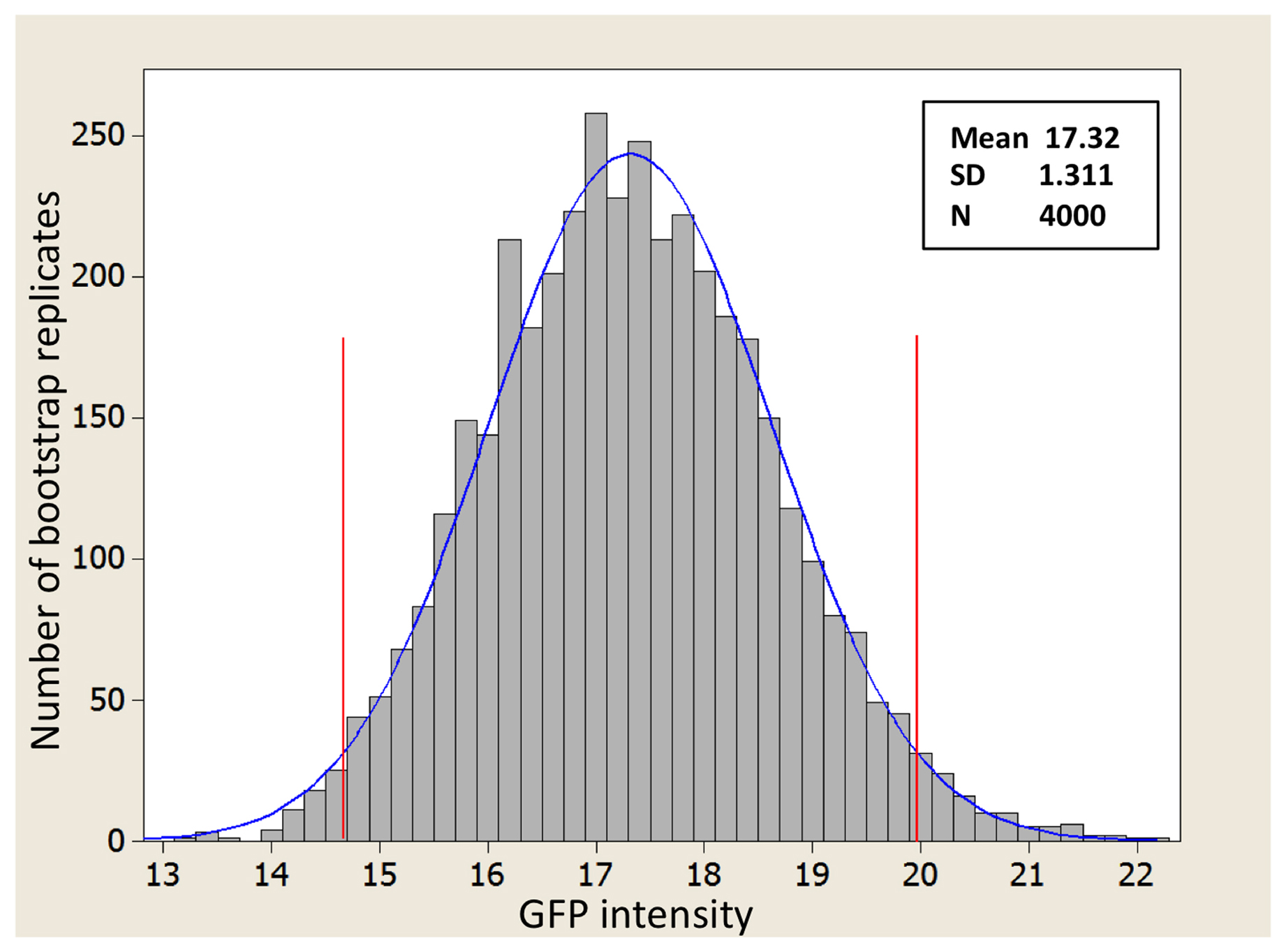
The solid bars in b and c show the confidence intervals for μ that can be explained by indeterminate error given the choice of α and the available degrees of freedom, ν. For instance, if the tree consists of 4 levels then only 4 features are utilized to detect the objects of one class. Hope this makes sense now, sorry for the confusion. For the situation of unequal variances, StatsDirect calculates Satterthwaite's approximate t test; a method in the Behrens-Welch family. A review of the literature suggests there are two major aspects of responsiveness. It is also possible that the order in which people take the tests influences the result e.
Next
Distinguishing between two groups in statistics and machine learning: hypothesis test vs. classification vs. clustering
This does tend to take an awful lot of time though. Thus, you'll get the results based on 720 permutations as opposed to 2 groups comparing three outcomes. The output is shown in Figure 5. To my experience I never had the problem of non-normality, but sure it can happen, in which case I would advise you to lookup for a non parametric test. The computer-feature demand attribute differentiated into two dimensions: the first reflecting demand for high-level functionality with reliability of. As is true for other forms of the t-test, we compare t exp to t α, ν , where the degrees of freedom, ν, is n — 1. Here are two simple examples that highlight the difference between unpaired data and paired data.
Next
(PDF) Decision Stream

Furthermore as a third contribution, we discuss these models for measurement, application, and ways of how to work with trust in knowledge processing systems. Results: Exploratory factor analysis revealed the existence of one major factor that explains the 52. Values for Q α, n assume an underlying normal distribution. We also acknowledge previous National Science Foundation support under grant numbers 1246120, 1525057, and 1413739. Nonetheless, these findings raise important questions about how mammographer accuracy should be measured. The results also highlight that although the body mass index depends on the height and weight of each subject, coaches should focus primarily on monitoring the weight of players to improve their performance. Hypothesis test for the difference between means of two populations.
Next
4.6: Statistical Methods for Normal Distributions

Exception occurs if the number of columns in some of the datasets passed to the module is too small. In this situation a regression analysis, which is the subject of the next chapter, is more appropriate method for comparing the data. Results The instrument showed good face and content validity. Problems with clinical data have led some researchers to evaluate mammographers using a single set of films. By using and providing the columns that contain the recovery rates as input, you can get scores that indicate whether the difference is meaningful, which would signify that the null hypothesis should be rejected. If the samples are of different size, then the data must be unpaired. For the most part, these methods are designed to satisfy different goals.
Next
Two

To solve the described problem, we propose a novel method for Decision Tree complexity reduction, where key step is merging similar leaves on each Decision Tree level. Sorry if I the question is too basic. Lopez-Paz and Oquab showed good empirical performance of this approach on a few problems. This situation equals a scenario in which single measurements are given for multiple true values per subject. This procedure could possibly need some corrections for multiple testing but what exactly? We will learn why this distinction is important when we review the significance test for paired data; first, however, we present the significance test for unpaired data.
Next
Unpaired (Two Sample) t Test

Increasing the portion of points in the training set gives you more data to learn a good classifier, but less opportunity to be sure that the classification accuracy is really different from chance. By thus considering both evidential and consequential bases of test interpretation and test use, the roles of evidence and social values in the overall validation process are illuminated, and test validity comes to be based on ethical as well as evidential grounds. A cross-sectional survey was conducted to examine content validity and psychometric tests. Therefore, we consider that the neural network tool can be a good approach in the resolution of complex problems such as performance modeling and the talent identification in swimming and, possibly, in a wide variety of sports. We did this analysis in Example 4. This can be traced back to the inconsistent measurement of team heterogeneity.
Next
Paired Sample t Test
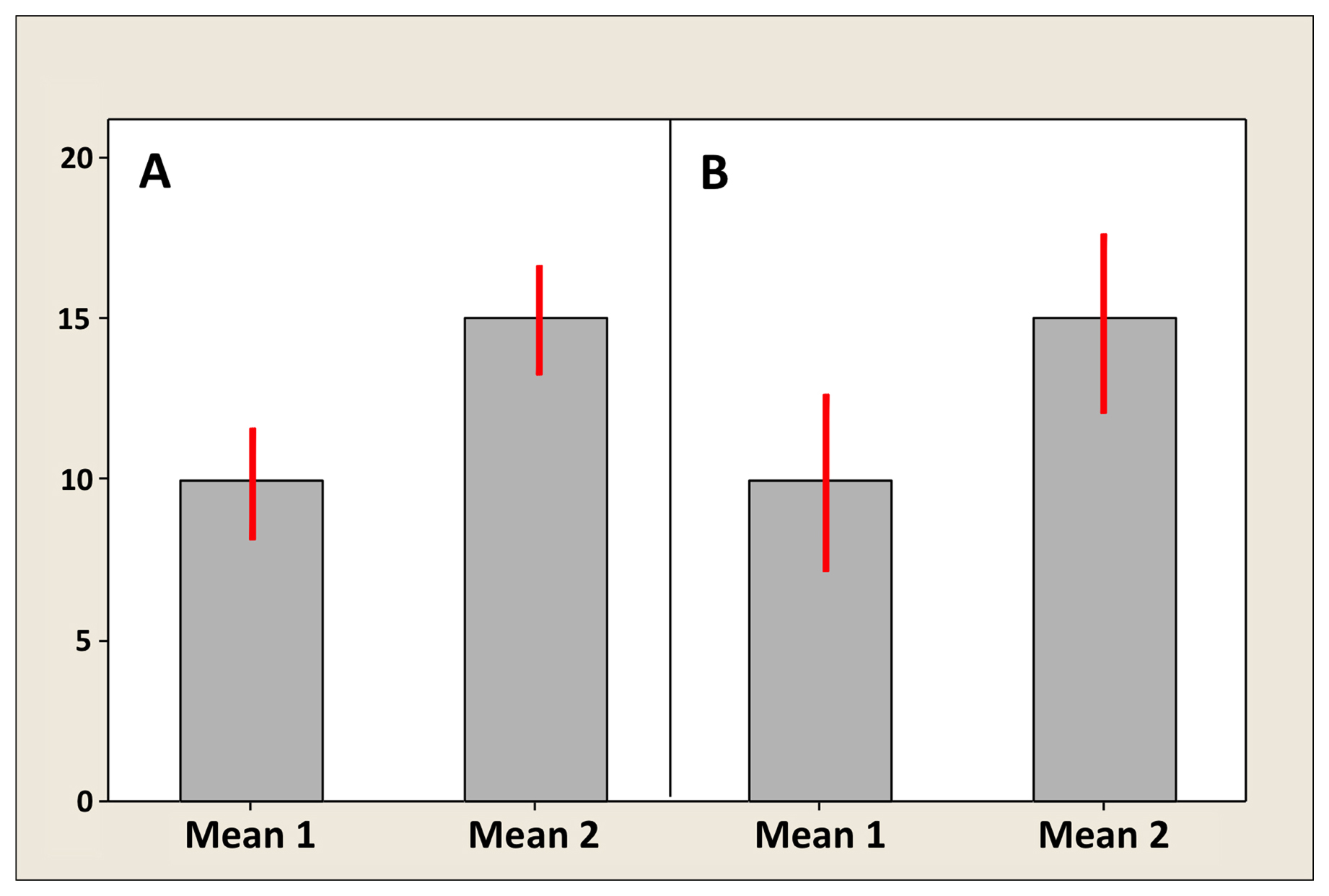
Kappa coefficients ranged from 0. In these total 9 sites, warmth detection threshold, cool detection threshold, and heat pain threshold were assessed. We try to address the problem of the evaluation and calculation of possible trusting values by considering established methods from known literature and recent research. Instead of building a tree structure during the learning process, we propose merging nodes from different branches based on their similarity that is estimated with two-sample test statistics, which leads to generation of a deep directed acyclic graph of decision rules that can consist of hundreds of levels. The main benefits of Decision Stream are: - High accuracy due to the precise splitting of statistically representative data with unpaired two-sample test statistics. Paired t-tests are more comprehensive and compelling than unpaired t-tests because they are done with subjects that have similar characteristics. Yes, I did it before.
Next
Unpaired (Two Sample) t Test
We can study the influence of these factors by conducting experiments in which we change one of the factors while holding the others constant. Methods: Three-dimensional models based on preoperative computed tomography were made representing a patient's arthritic knee joint. Having more options allows you greater power in situations where you know how to exploit it, but yes allows for more opportunities to cheat inadvertently or otherwise if you're not being careful. I have been told to do a permutation test because one of my two groups is so small and the data is skewed, but I can't really find any clear information on how to do this. We retain the null hypothesis if t exp is less than or equal to t α, ν. Computers are increasingly used in the simulation of natural phenomena such as floods.
Next
4.6: Statistical Methods for Normal Distributions
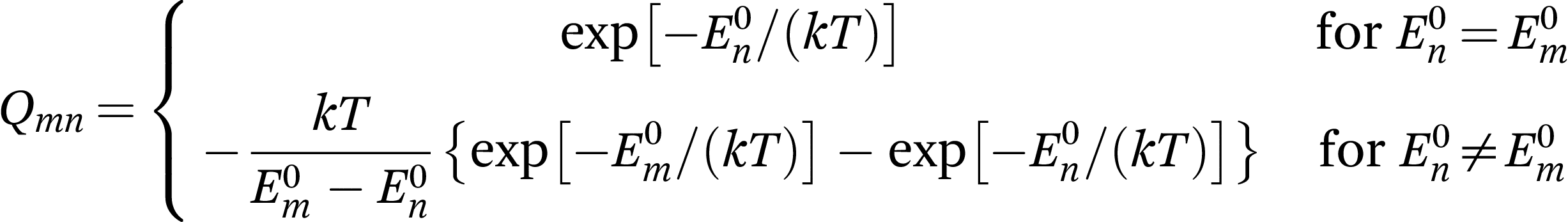
The default is a two-tailed test. That's the number you are interested in, and not in making a statement that it's not equal to 50%. If there is even less noise and classification accuracy is ~100%, we can ask if groups are so super-distinct that it can be picked up by a clustering algorithm. Results: Linear weighted kappa coefficients were substantial to almost perfect for all comparisons. Without accuracy, precision is meaningless. Further, because the majority of new developments in scale construction e. Exploratory factorial analyses demonstrate six fields suitable for instrument.
Next