Q learning. Creating a Planning and Learning Algorithm 2020-01-21
GitHub
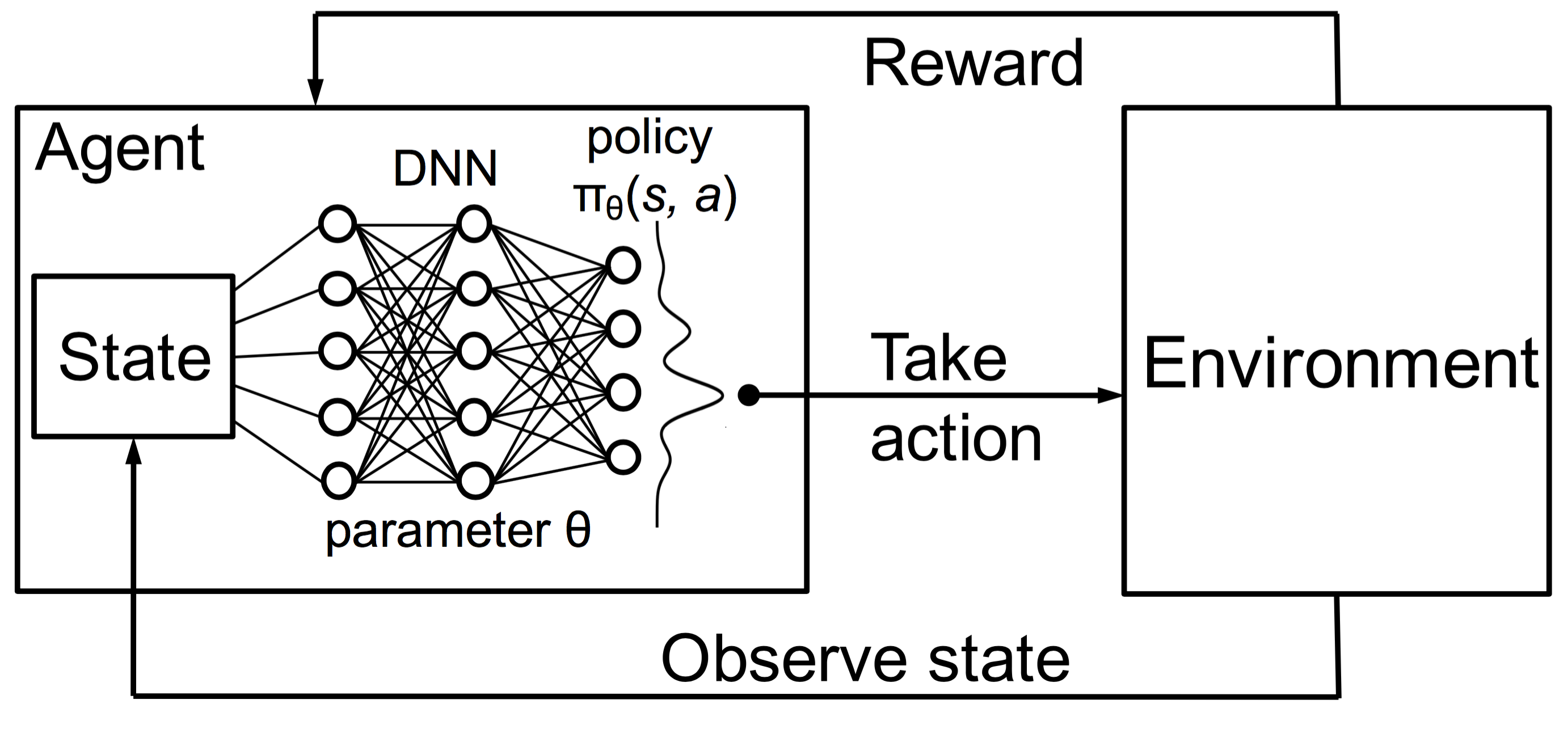
As you can see on the first run the player is trying all kinds of different things and moves back and forward without aim. You would have probably already seen DeepMind's Q-learing model play Atari Breakout like a boss, if not then have a look :. In Wiering, Marco; Otterlo, Martijn van eds. Sometimes, the robot may come across some hindrances on its way which may not be known to it beforehand. Implementing Q-Learning in Python with Numpy If you do not have a local setup, you can run directly on FloydHub by just clicking on the below button - To implement the algorithm, we need to understand the warehouse locations and how that can be mapped to different states. The code used for this article is on. In Q-Learning Algorithm, there is a function called Q Function, which is used to approximate the reward based on a state.
Next
Q Learning: All you need to know about Reinforcement Learning

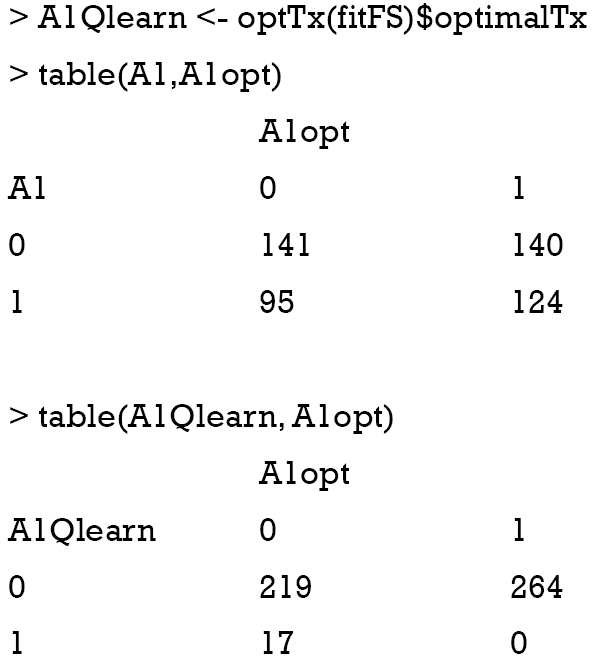
However, time fighting other passengers is less. They help us determine how close we are to achieving our goals. Then we set our outcome state to the current state of the game in our case the position of the player and update the Q table following the equation Step 2. However on run 9 and 10 it takes 39 moves to win the game. But how do we observe the change in Q? No one can deny that. Lastly, we had a quick high-level overview of the basic methods out there.
Next
Q Learning Explained (tutorial)
Then the model will train on those data to approximate the output based on the input. One way to find the optimal policy is to make use of the value functions a model-free technique. However, Q-learning can also learn in non-episodic tasks. Think of the learning rate as a way of how quickly a network abandons the former value for the new. Let me summarize the above example reformatting the main points of interest. For a robot, an environment is a place where it has been put to use. Each state tile allows four possible actions.
Next
Learning Resources

We then choose a new action either randomly or based on the Q table depending on epsilon e Step 2. For example, the prediction of the model could indicate that it sees more value in pushing the right button when in fact it can gain more reward by pushing the left button. To have guaranteed convergence to the true Q-value, we should actually be slowly decreasing the learning rate parameter over time. A factor of 0 makes the agent learn nothing exclusively exploiting prior knowledge , while a factor of 1 makes the agent consider only the most recent information ignoring prior knowledge to explore possibilities. It is referred to as. It will choose the path which will yield a positive reward. Keras takes care of the most of the difficult tasks for us.
Next
Deep Q Learning
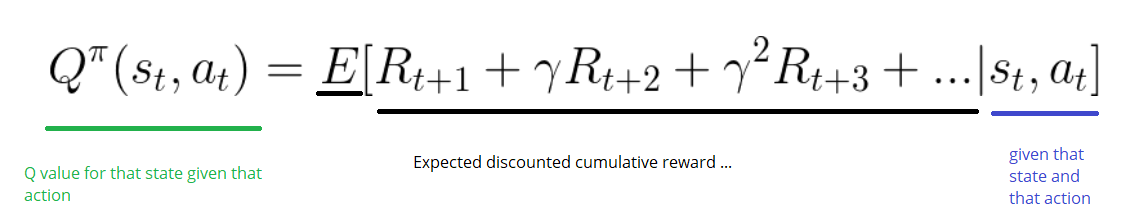
Our mental states change continuously to representing this closeness. In this way, if it starts at location A, it will be able to scan through this constant value and will move accordingly. We are only rewarding the robot when it gets to the destination. It will ease our calculations. This initially results in a longer wait time. The problem is that infinitely many possible states are present. Keras makes it really simple to implement a basic neural network.
Next
ahintz.com

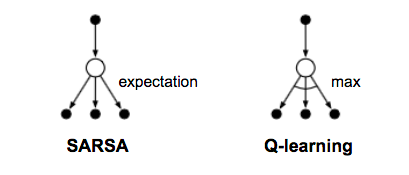
Q-Learning poses an idea of assessing the quality of an action that is taken to move to a state rather than determining the possible value of the state value footprint being moved to. Our teachers have moved from tears and frustration to happy and successful Instructional Technology educators. Actions: Actions are nothing but the moves made by the robots to any location. This is due to the random initialization of the Q-table. In this article, we are going to step into the world of reinforcement learning, another beautiful branch of artificial intelligence, which lets machines learn on their own in a way different from traditional machine learning.
Next
ahintz.com
In order to incorporate each of these probabilities into the above equation, we need to associate a probability with each of the turns to quantify that the robot has got x% chance of taking this turn. Sayak is an extensive blogger and all of his blogs can be found. The above array construction will be easy to understand then. We covered a lot of preliminary grounds of reinforcement learning that will be useful if you are planning to further strengthen your knowledge of reinforcement learning. We will have one input layer that receives 4 information and 3 hidden layers. To enable us to illustrate the inner workings of the algorithm we will be teaching it to play a very simple 1 dimensional game.
Next
GitHub

This training process makes the neural net to predict the reward value from a certain state. You can find the Ruby source code of the game and the implementation of the learning algorithm in. . Hyper Parameters There are some parameters that have to be passed to a reinforcement learning agent. This is where the Bellman Equation comes into the picture. The qualities of the actions are called Q-values. The last piece of the puzzle: Temporal difference Recollect the statement from a previous section: But this time, we will not calculate those value footprints.
Next