Apache flink. What is Flink? Apache Flink Tutorial Guide for Beginner 2019-11-20
How to setup or install Apache Flink

Before we get to my five key takeaways, though, a little background is in order: What is Flink and what were we building with it? Program It is a piece of code, which you run on the Flink Cluster. In a short time of 2 years since its initial release May 2014 , it has seen wide acceptability for real time, in-memory, advanced analytics — owing to its speed, ease of use and the ability to handle sophisticated analytical requirements. Release Notes Release notes cover important changes between Flink versions. We wrote code that checked that the environment variables were set before initializing. To set up Java in your machine, please refer. Apache Spark and Apache Flink are both open- sourced, distributed processing framework which was built to reduce the latencies of in fast data processing. This issue is unlikely to have any practical significance on operations unless the use case requires low latency financial systems where delay of the order of milliseconds can cause significant impact.
Next
What is Flink? Apache Flink Tutorial Guide for Beginner
The Usage Calculator is an application that reads from containing usage metadata from , , and agents; the app aggregates data for 24 hours and then writes that data to a Kafka topic containing daily usage data. Visa exchanges, sensor estimations, machine logs, or client cooperation on a site or portable application, this information are produced as a stream. I am happy to say Flink has paid off. It takes information from circulated stockpiling. At the point when a procedure comes up short, another procedure is naturally begun to take once again its work. That is to say, the reading and processing of data does not begin until the execute method is called on the environment.
Next
What is Apache Flink?

The Flink software is open source and adheres to 's licensing provisions. This is the center layer of flink which gives conveyed preparing, adaptation to internal failure, unwavering quality, local iterative handling ability, and so forth. That does not mean Kappa architecture replaces Lambda architecture, it completely depends on the use-case and the application that decides which architecture would be preferable. In a deployed cluster, these operators run on separate machines. If a node, application or a hardware fails, it does not affect the cluster. In the accompanying, we portray these structure hinders for stream preparing applications and disclose Flink's ways to deal with handle them. Conclusion In this Flink Tutorial, we have seen how to set up or install the Apache Flink to run as a local cluster.
Next
What is Apache Flink?

Flink's github repository Get the Repository — shows the community doubled in size in 2015 — from 75 contributors to 150. As developers, we came up to speed on Flink quickly and were able to leverage it to solve some complex problems. Henceforth, disappointments are straightforwardly dealt with and don't influence the rightness of an application. In a webinar, consultant Koen Verbeeck offered. A fixed or improved rendition of an application can be restarted from a savepoint that was taken from a past variant of the application. For this tutorial, we chose the Hadoop version 2. Hadoop is an open source distributed processing framework that manages data processing and storage for big data applications.
Next
What is Apache Flink?
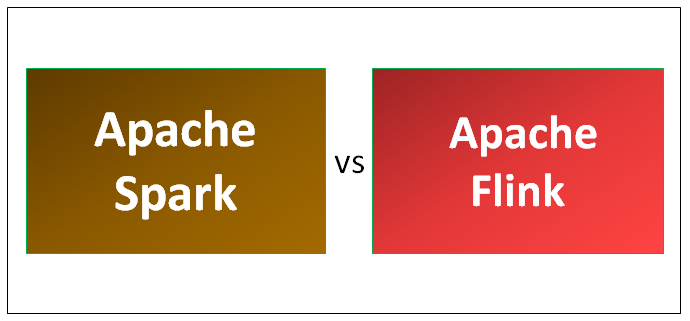
At any later point in time, the application can be continued from the savepoint. It was the first time that users were allowed to create their own data on the internet and it was ready to be consumed by a data hungry audience. One of the biggest challenges that big data has posed in recent times is overwhelming technologies in the field. We discussed several approaches but decided to merge data from the Usage Calculator with data from another stream in the New Relic ecosystem that stored account information. Deployment Before putting your Flink job into production, read the. Apache Flink is the cutting edge Big Data apparatus, which is also referred to as the 4G of Big Data.
Next
Apache Flink vs Spark

As I mentioned earlier, Flink allows you to run massive parallel operations on your data thanks to a job manager that coordinates multiple task managers, the latter of which run user-defined operations on the data Flink passes into them. A successful project The Account Experience team is happy with our choice to embrace Flink. Conclusion Apache Flink comes with its own set of advantages and disadvantages. We compose it in Scala. Handling of limited streams is otherwise called clump preparing.
Next
Apache Flink Training

Flink provides very varied features related to time. Prior to download, we have to choose a binary of Apache Flink, based on the requirements. One of the key differentiators for Spark is its ability to hold intermediate results in-memory itself, rather than writing back to disk and reading from it again, which is critical for iteration based use cases. A savepoint is a reliable preview of an application's state and thusly fundamentally the same as a checkpoint. According to the wersm we are social media report, Facebook gets more than 4 million likes in a minute! Not a big deal, right? These facts enhance its reputation as the most actively developed and adopted open source data tool. Specifically, we needed two applications to publish usage data for our customers.
Next
[Unpatch] Apache Flink remote code execution vulnerability alert • InfoTech News
It is principally utilized for appropriated preparing. To put things in another perspective, about 90% of all data existing in this world, was created in the last two years, even though the World Wide Web has been accessible to public for well over two decades. All things considered, it is an uncommon instance of Stream preparing where we have a limited information source. There are so many platforms, tools, etc. Flink builds batch processing on top of the streaming engine, overlaying native iteration support, managed memory, and program optimization.
Next
Apache Flink 1.9 Documentation: Apache Flink Documentation
Flink has several operators for merging streams; we used the CoFlatMapFunction, which takes data from two joined streams and allows you to define the result of the mapping. It is responsible to send the status of the tasks to JobManager. Flink applications can process recorded or constant streams. With the inevitable boom of Internet of Things IoT space, Flink user community has some exciting challenges to look forward to. Be prepared: Flink uses lazy evaluation to separate configuration and execution Flink orchestrates operators running in parallel. It offers up to five-fold boost in speed when compared to the standard processing algorithm. This speaks volumes of its worldwide acceptability, which is on the rise.
Next